Deploy MeiliSearch with Dokku for production
Run open-source, fast and typo-tolerant search-engine with modern open-source PaaS


I'll show you how to create and setup Dokku app for MeiliSearch deploying and how I use it with Python.
Dokku is a free open-source self-hosted Heroku alternative which I use in all my production environments.
I use MeiliSearch in one of my Telegram bots, where I expect a search query from a user (with typos of course). Since I deploy everything (including Telegram bots) with Dokku, I found a way how can I deploy MeiliSearch as well.
Step-by-step deployment with Dokku
I assume you already have Dokku installed. Otherwise, check this tutorial.
Create Dokku app and attach domain you'll use in production:
dokku apps:create ms
dokku domains:set ms ms.okhlopkov.comMeiliSearch requires some environment variables to run in production. MEILI_MASTER_KEY is the token (password) you'll use to access your service. I use these values:
dokku config:set ms \
MEILI_ENV=production \
MEILI_MASTER_KEY=followmeontwitter \
MEILI_NO_ANALYTICS=true \
MEILI_NO_SENTRY=trueMeiliSearch stores all the data it needs in data.ms file so we need to save it outside of the docker image for persistence.
dokku storage:mount ms /root/data.ms:/data.msNow everything is set up, we can start to deploy the MeiliSearch from the official Docker image and proxy its 7700 port to 80:
dokku git:from-image ms getmeili/meilisearch
dokku proxy:ports-set ms http:80:7700Then you can add Letsencrypt if you like:
dokku letsencrypt:enable msOr add Cloudflare certificates if you prefer (read the instruction here):
dokku certs:add ms < certs/okhlopkov.com.tar
dokku proxy:build-config msIf you want to update MeiliSearch, just deploy from image again:
dokku git:from-image ms getmeili/meilisearchHow to use MeiliSearch
I'll show you how to add data and send search queries using Python. This is how I do it inside my Telegram bot:
MS_URL = "https://ms.okhlopkov.com/"
MS_SECRET = "followmeontwitter"
import meilisearch
client = meilisearch.Client(MS_URL, apiKey=MS_SECRET)
index = client.index('crunchbase_orgs')Imagine that you prepared the list of objects dictionaries that you'd like to index. Now you need to upload your data to MeiliSearch. I'd suggest to batch upload your data: check out the snippet:
from tqdm.notebook import tqdm
def chunks(lst, n):
"""Yield successive n-sized chunks from lst."""
for i in range(0, len(lst), n):
yield lst[i:i + n]
DATA_TO_UPLOAD = [{ your data here }, { and here }, ....]
chunk = 1000
for i, rch in tqdm(
enumerate(chunks(res, chunk)),
total=int(len(DATA_TO_UPLOAD) / chunk),
):
upd = index.add_documents(rch)⚠️ Important: if you have 100k-1M data rows, it will require ~4-8 hours to index them all. Yes, MeiliSearch has a fast search but a slow insert. And it's ok.
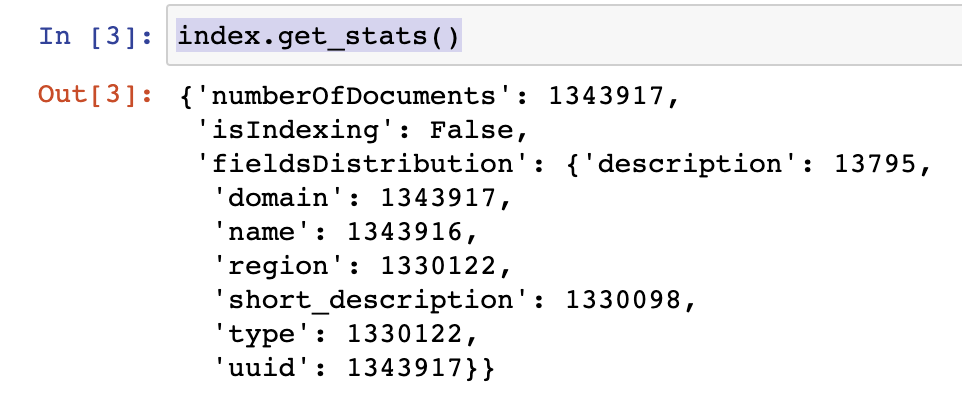
After you insert data to the index, you can observe its stats:
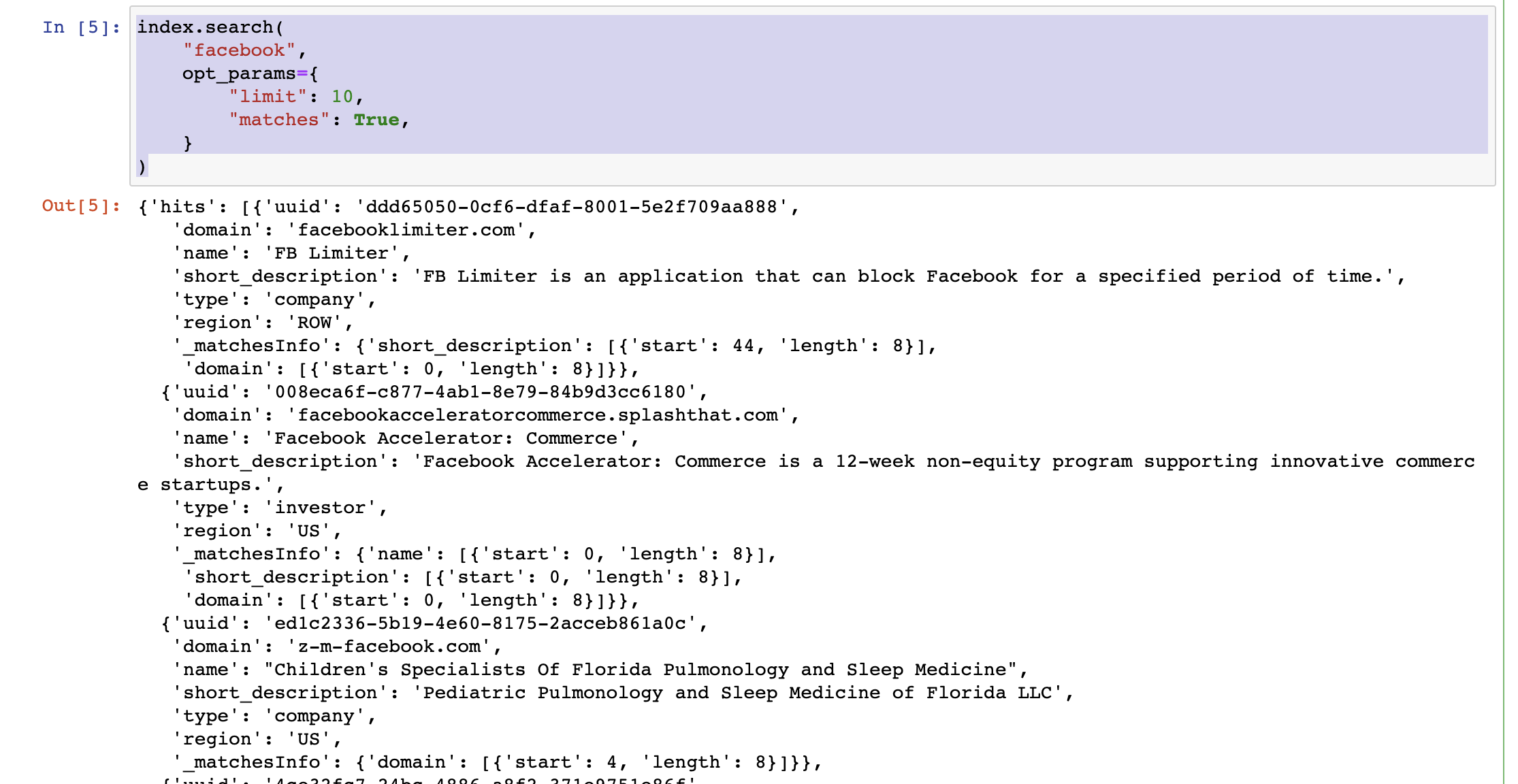
After all indexing is done, you can start to query your data:
Got questions? Please ask them on Twitter.
Dan Okhlopkov — AI agent practitioner. Building tools for TON Blockchain analysis and Telegram automation.